
Apr 22, 2026

There's a slide I show in almost every talk I give. Two columns. On the left: a word generator. On the right: a simulation model. Same input, very different outputs, completely different level of trust you can place in the result.
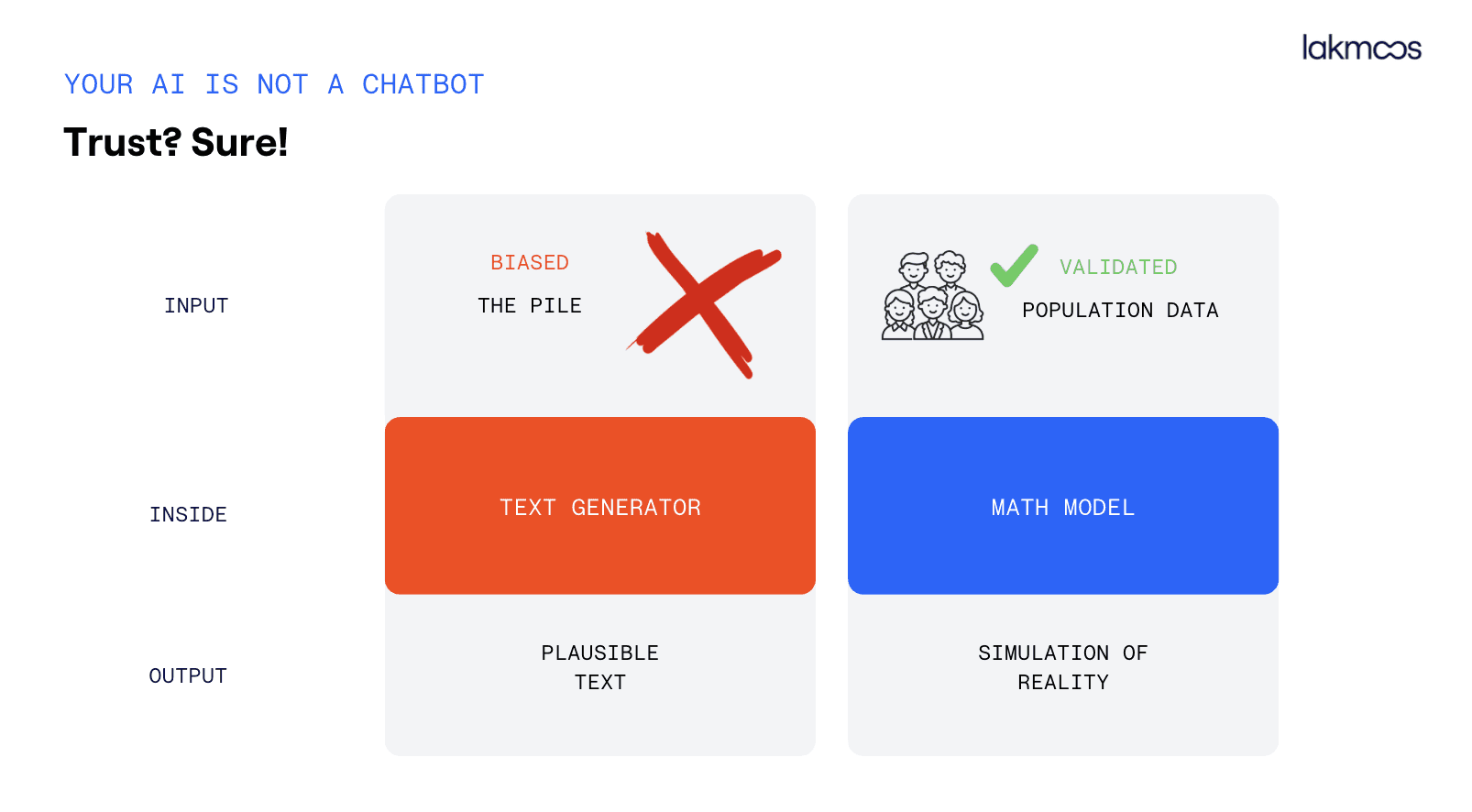
Every time I show it, someone in the room nods slowly, the kind of nod that means oh, that's what's been bothering me.
Because a lot of teams have tried using ChatGPT to simulate a customer. They've typed something like "respond as a 35-year-old woman from Prague who drives a mid-range car and is considering switching banks." They've gotten back a paragraph that sounded reasonable. And then they've made a decision based on it.
I understand the appeal. It's fast, it's cheap, it feels like research. But it isn't. And the difference matters more than most people realize.
Sherlock doesn't guess. He reasons.
You know the scene. Sherlock looks at a stranger for three seconds and announces that the man is married, recently returned from abroad, works in finance, and is under stress. The audience is baffled. Watson asks how he could possibly know.

The answer is: he didn't know. He reasoned from available data. A clean shirt ironed by someone else. Female perfume on the collar. A particular kind of watch tan. Each signal, on its own, means little. Together, filtered through everything Sherlock has learned about how the world works, they point clearly in one direction.
Now imagine the same task given to a large language model.
Available data: the letters s, r, t, i.
Best guess: This man is m____ed. 40% married. 30% merged. 20% mingled.

That's structurally what a language model does. It predicts the most probable next token given the tokens before it. It has been trained on enormous amounts of text, mostly from the English-speaking internet, and it has learned which words tend to follow which other words. It is extraordinarily good at generating text that sounds right.
But sounding right and being right are two completely different things.
The foundation determines the output
When you use a chatbot to simulate a customer, three things are working against you.
First, the starting point. A large language model is trained on words from the internet. That corpus skews heavily toward English, toward certain demographics, toward people who write things down. If you're trying to understand a Czech banking customer, a Polish car buyer, or a German energy consumer, the training data isn't built around them. The model will approximate, but the approximation is biased in ways that are invisible to you.
Second, what's happening inside. A language model is a word generator. When it produces a "response" from your synthetic persona, it isn't running a simulation of that person's decision-making. It's predicting which words a person like that might plausibly say, based on what it's seen before. There's no mathematical model of behaviour underneath. There's no logic that connects values, constraints, past experience, and context into a consistent response. There's just a very sophisticated autocomplete.
Third, what you actually get. The output is probable text. It might look like an insight. It might even accidentally be correct. But you have no way of knowing when it's correct and when it isn't, because there's no ground truth to compare it against, and no mechanism inside the model that would tell you its own confidence level on anything domain-specific about your customer.
What a simulation model actually does
A simulation model starts in a different place entirely.
Instead of training data from the internet, you start with a validated dataset about a real population. Survey data, behavioural data, segmentation data — structured information about how specific groups of people actually think, decide, and act. This is the foundation.
On top of that foundation, you build a model that can reason about that population. Not generate text about them, reason about them. When you ask a question, the model applies what it knows about this group's values, their constraints, their typical decision patterns, and produces a distribution of responses. Not a single fluent paragraph, but a statistically grounded answer that reflects the actual variance in how people in this segment respond.
The output isn't probable text. It's a simulation of reality.
Why this distinction is worth fighting for
Let me give you a concrete example of why it matters.
Imagine you're a product team deciding whether to introduce a new pricing tier. You want to know: what percentage of your target segment would consider switching to a competitor if you raised prices by 15%?
You could ask a chatbot. It will give you an answer. It might say something like "many customers in this segment are price-sensitive and would likely explore alternatives." That sounds like an insight. It is, in fact, a sentence.
Or you could ask a simulation model built on validated data about your actual customer base. It will tell you that 34% of segment A would actively compare competitors within 30 days, while segment B shows significantly lower churn intention, driven primarily by inertia and switching costs rather than loyalty.
One of those outputs can inform a pricing decision worth millions. The other one cannot.
The Nielsen Norman Group has a useful framework for this: before using generative AI for a task, ask whether it matters if the output is true. If it does matter — if you're going to act on the result — you need to be able to verify it, or you need a system that was designed to produce verifiable outputs in the first place.
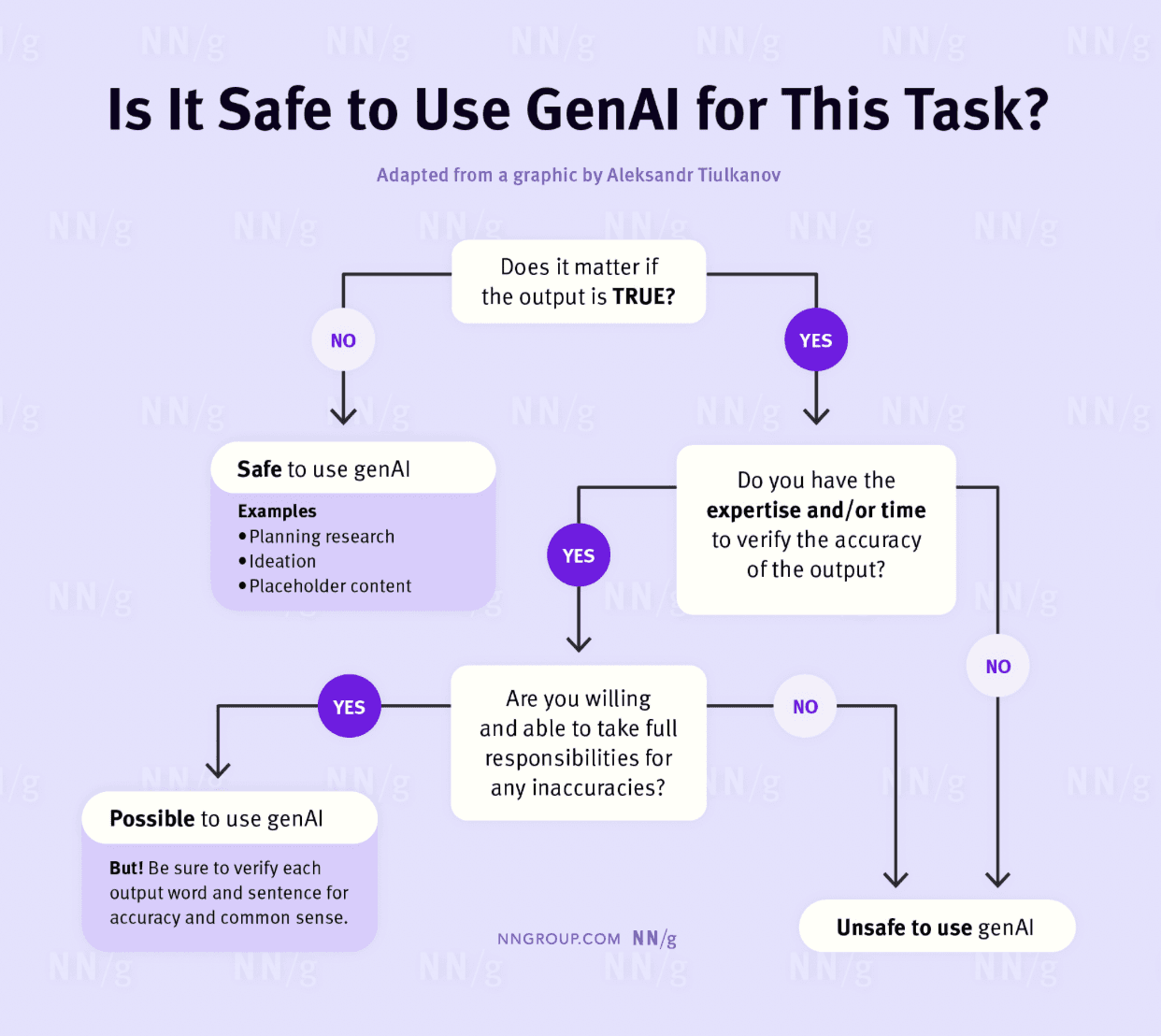
For most of the things design and research teams actually use synthetic personas for — validating assumptions, testing concepts, understanding how segments respond to change — it matters very much whether the output is true. And a chatbot, by design, cannot guarantee that.
This isn't an argument against AI. It's an argument for the right AI.
I want to be clear: large language models are extraordinary tools. For drafting, for summarising, for brainstorming, for generating creative options, they're genuinely transformative. I use them constantly.
But AI is not one thing. It's a broad space with many different techniques, built for many different purposes. A recommendation algorithm is AI. A fraud detection system is AI. A medical imaging classifier is AI. None of those are language models, and using a language model for those tasks would be like doing financial forecasting in a Word table. It's technically possible. But you know why nobody does it.
The same logic applies to synthetic personas. If you want a customer voice that you can actually make decisions from, one that represents a real population, that produces statistically meaningful outputs, that you can trust when the stakes are high, you need a simulation model, not a chatbot.
The terminology is messy. Silicon samples, digital twins, AI panels, synthetic personas, the industry hasn't settled on a name yet. That's fine. What matters isn't the label. What matters is what's underneath: who does it represent, and how did it get there?
The question worth asking
In 2025, we generated one billion synthetic responses for enterprise teams across automotive, banking, insurance, and retail. The teams that got the most value weren't the ones who were most excited about AI. They were the ones who asked the most precise questions about what was actually happening inside the model.
What data was it trained on? What population does it represent? How does it handle uncertainty? Can I see the distribution of responses, not just the average? What's the confidence interval?
Those are the questions a researcher asks. They're also the questions that separate a useful synthetic persona from a very fluent guess.
The next time someone on your team suggests using a chatbot to simulate a customer, ask those questions. The answers will tell you everything you need to know.
Kamila Zahradníčková is the founder of Lakmoos AI, a research technology company that builds synthetic panels powered by neuro-symbolic AI. Lakmoos has delivered over 1 Bn synthetic responses to enterprise teams across Europe.

